


我以前寫服務(wù)的時候,習(xí)慣性就用 UUID 來做主鍵或者分布式 ID,感覺挺自然的嘛,Java 里一行 UUID.randomUUID() 就能搞定,Python 里 uuid.uuid4() 也很順手。可是時間長了,問題一個個暴露出來,才發(fā)現(xiàn) UUID 雖然“方便”,但真不一定是最佳選擇。
UUID 的那些小坑
先說 UUID,它是 128 位,通常寫成 36 個字符那種帶橫杠的字符串,比如:
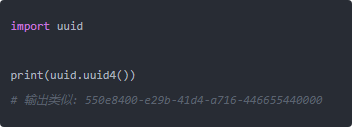
看上去沒啥問題,但問題有幾個:
- 太長了:36 個字符,在數(shù)據(jù)庫里當(dāng)主鍵,不管是索引還是存儲,開銷都挺大。
- 無序性:UUID 本質(zhì)上是隨機(jī)的(尤其是 v4),寫到數(shù)據(jù)庫里會導(dǎo)致索引亂跳,插入性能直線下降。
- 可讀性差:光看 UUID 完全沒法區(qū)分誰先誰后,排個序都不現(xiàn)實。
這些小坑疊在一起,就讓 UUID 在高并發(fā)、大量寫入的業(yè)務(wù)里挺難受。
ULID 登場
后來我接觸到 ULID(Universally Unique Lexicographically Sortable Identifier),說白了,它和 UUID 一樣是全局唯一 ID,但設(shè)計上更貼合實際場景。
ULID 的幾個優(yōu)勢:
- 長度更短:26 個字符,比 UUID 少一截。
- 可排序:它的前半部分是基于時間戳生成的,天然有序,插入數(shù)據(jù)庫更友好。
- 可讀性好:ULID 是 Crockford’s Base32 編碼,不會有大小寫混亂問題,看起來干凈多了。
舉個 Python 的例子,先裝個庫:
然后:
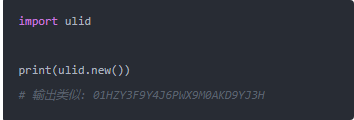
是不是比 UUID 短一些,而且字母數(shù)字組合看起來也沒那么亂。
性能和排序的對比
UUID 在數(shù)據(jù)庫里有個老毛病:因為它隨機(jī),寫入時會讓索引樹不停分裂,寫多了性能直接掉下來。ULID 前半部分是時間戳,天然就順序增長,索引幾乎是線性擴(kuò)展的。
比如你要存一批訂單數(shù)據(jù),用 ULID 作為主鍵,后續(xù)查詢“最近的訂單”,直接 ORDER BY id DESC 就行了;用 UUID 就沒這個優(yōu)勢。
我自己測試的時候,PostgreSQL 下用 UUID 做主鍵,插入幾百萬條后,索引膨脹得厲害,查詢也慢。換成 ULID,性能穩(wěn)得多。
代碼里的應(yīng)用場景
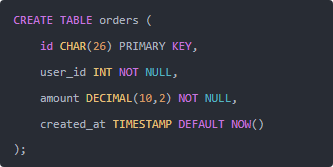
比如建表的時候:
Python 里插入:
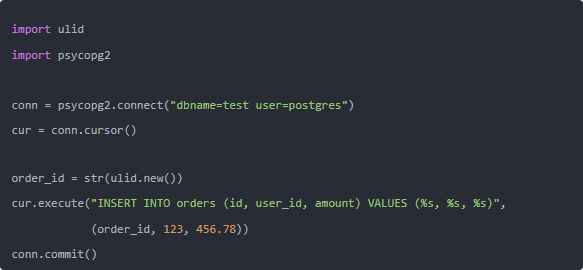
這樣每個訂單都有一個可排序、全局唯一的 ID,數(shù)據(jù)庫層面也不會卡。
什么時候該用 ULID?
不是說 UUID 就完全不能用了,如果你是那種“無狀態(tài)、臨時 ID”的場景,用 UUID 隨便搞搞也無所謂。但如果是:
- 數(shù)據(jù)庫主鍵
- 日志追蹤 ID
- 分布式系統(tǒng)里需要唯一 ID 且要排序
那 ULID 基本就是完美替代品。
我現(xiàn)在新項目里基本就不考慮 UUID 了,直接用 ULID,省心省力,還順便優(yōu)化了數(shù)據(jù)庫性能。你要還在用 UUID,當(dāng)心哪天線上寫入卡得你懷疑人生。
以上就是“放棄使用UUID,ULID才是更好的選擇!”的詳細(xì)內(nèi)容,想要了解更多Python教程歡迎持續(xù)關(guān)注編程學(xué)習(xí)網(wǎng)。
掃碼二維碼 獲取免費視頻學(xué)習(xí)資料

- 本文固定鏈接: http://www.wangchenghua.com/post/13524/
- 轉(zhuǎn)載請注明:轉(zhuǎn)載必須在正文中標(biāo)注并保留原文鏈接
- 掃碼: 掃上方二維碼獲取免費視頻資料